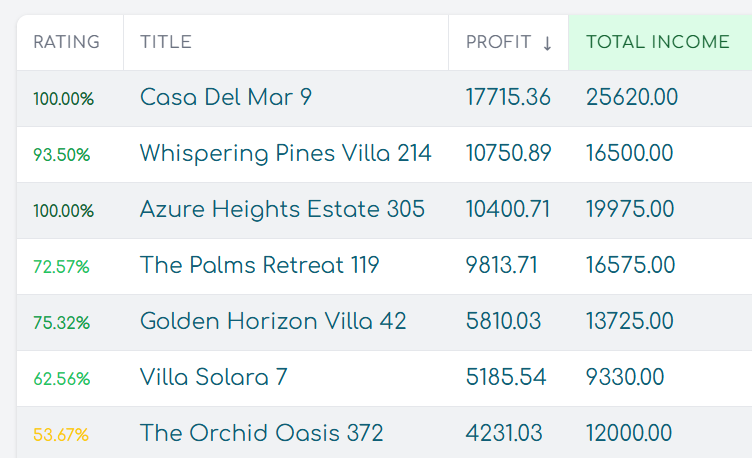
The Alva backend is the system that turns a scanned barcode into a personalized health risk assessment. That sounds like a single step, but it involves chemical identification, vector similarity search, multi-factor AI scoring, user health profiling, and async job processing — all of which has to finish fast enough that someone standing in a store aisle gets a useful answer before they lose patience.
What the backend is responsible for
- UPC barcode lookup and ingredient extraction
- Chemical identification through vector similarity search against a curated database
- PFAS and harmful chemical detection using OpenAI embeddings and pgvector
- Multi-factor risk scoring powered by AI analysis of toxicity, concentration, exposure, and user-specific health conditions
- Async job processing so product scans do not block the client
- User management, health profiles, collections, and product discovery
- Push notifications when scan results are ready
How the risk detection works
The core of the system is a pipeline that takes a raw ingredient list and turns it into a structured risk assessment.
When a product is scanned, the backend extracts ingredients from the UPC lookup, translates them if needed, and runs each ingredient through a vector similarity search against a PostgreSQL table of known chemicals. The chemical database stores EPA DTXSID records with 1536-dimensional embeddings generated by OpenAI’s text-embedding-3-small model. Matches above a 0.6 cosine similarity threshold are flagged as potentially harmful.
That gives a preliminary risk classification based on chemical match count. But the real value comes from the next layer: a weighted multi-factor risk score calculated through four parallel AI analyses.
How the multi-factor scoring works
The backend calls four separate AI-powered assessments and combines them into a single risk score:
- Toxicity analysis (40% weight) — evaluates how harmful the detected chemicals are based on known toxicity data
- Ingredient concentration analysis (30% weight) — estimates how much of the problematic ingredient is likely present based on ingredient list ordering and product type
- Exposure analysis (20% weight) — considers how often and how long a user is likely exposed to the product
- Health risk analysis (10% weight) — personalizes the score using the user’s specific health conditions collected during onboarding
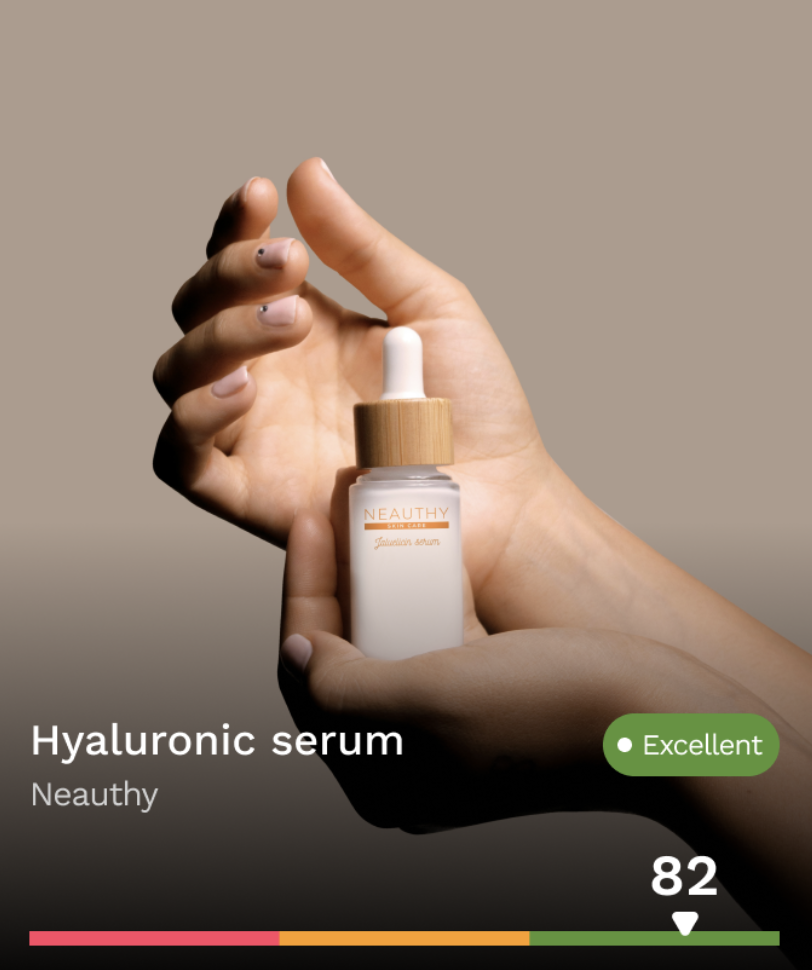
Each analysis returns a 1–10 score. The weighted total gives users a single number they can act on, backed by explanations they can read if they want the detail.
Why the architecture looks like this
The system runs on Node.js with Express, PostgreSQL with the pgvector extension, and OpenAI for both embeddings and analysis. Products are processed asynchronously: the client receives a job ID immediately and polls until the result is ready.
That async model matters because a full product analysis involves multiple external API calls — UPC lookup, ingredient translation, embedding generation, and four separate AI scoring requests. Doing that synchronously would make the scanning experience feel broken.
The chemical database is the foundation of the whole system. Each chemical record carries its own embedding vector, which means new ingredients can be matched semantically rather than requiring exact string matches. That is what makes the detection resilient to ingredient list variations, misspellings, and alternative chemical names.
What makes the system interesting
Most ingredient-checking products stop at a lookup table. Alva goes further by combining vector-based chemical matching with AI-powered contextual analysis and user-specific health personalization. The result is not just “this ingredient is bad” but “this ingredient, at this likely concentration, with this exposure pattern, matters specifically because of your health profile.”
That layered approach is what gives the product its credibility with over 2,300 active users and growing.